
多维查询的一种实现cube化
什么是多维查询呢?
比如计算pv,我们有统计sql:
1 | select count(1) from log; |
如果老板有一天想看一下哪些操作系统访问占比会比较大,我们有统计sql:
1 | select os,count(1) from log group by os |
假设还需要查看访问windows系统中,哪些地区的访问占比比较大,我们有统计sql:
1 | select location, count(1) from log where os = "windows" group by location |
多维分析就是从一个表中取多维数据进行计算的一个分析过程
olap的基本需求
olap就是在线分析处理,主要针对数据量大的离线数据,提供进行快速多维分析的能力。olap处理的数据一般是大量的离线数据,返回的速度在10s之内
- 下钻
下钻是一种分析的办法,比如,老板发现这两天网站pv下降很严重,需要看一下是哪个地区的pv下降的最严重,然后发现,广州贡献了绝大部分pv的减少,接着继续分析,需要看一下广州地区中哪种平台减少的多,经过层层分析,找出相关的问题
下钻总是从一个汇总表开始,不断固定一个维度进行展开操作
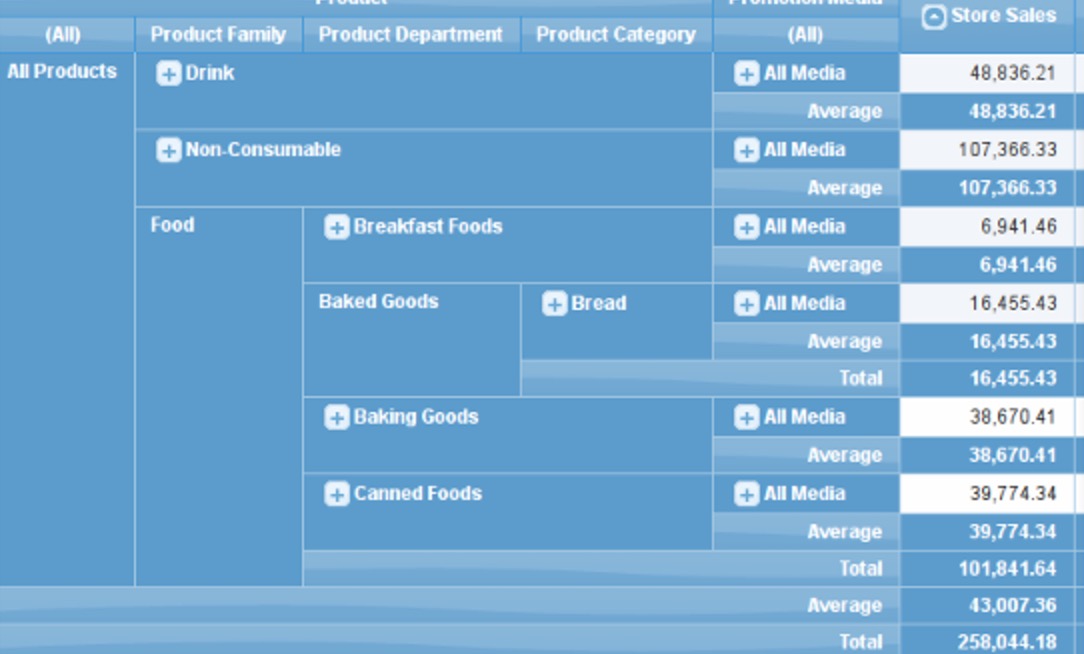
上图是pivot4j的截图 - 上卷
上卷就是向上汇总。是下钻的逆操作 - 切片
切片通过设置过滤条件,进行数据集裁剪,如果用sql实现,就是多写几个where条件 - 切块
切块也是设置过滤条件,不同的是,切块是截取字段中一些值或者一个区间,而切片只是截取一个值 - 旋转
数据查询允许二维表行列转换,类似于矩阵转置
打cube
cube化报表是实现olap的一种方式,通过将所有可能出现的查询缓存起来
实现方式
我们通过一个例子来说明如何实现:
表:web端访问日志,字段:日期(20161125,20161126,20161127),操作系统(windows,linux,osx),地区(广州,北京,上海),指标:pv
- 枚举所有的字段组合:(ALL表示该字段聚合)(总共444=64种组合)
- ALL_ALL_ALL
- 20161125_ALL_ALL
- 20161125_windows_ALL
- 20161125_windows_广州
- 20161125_windows_北京
- 20161125_windows_上海
- 20161125_linux_ALL
- ……
- 计算所有组合的pv
- 将计算结果保存到redis或者hbase
- 根据key查询pv
如何进行多维查询?
根据上述预处理过程,多维查询只需要将所有维度组合进行kv查询
如何进行下钻?
只需要枚举下钻维度,并重新组合成多个key进行逐条查询。比如说我们从ALL_ALL_ALL进行日期下钻,我们就枚举20161125_ALL_ALL,20161126_ALL_ALL,20161127_ALL_ALL进行返回
为啥需要redis或者hbase
因为预处理了所有的字段组合的结果,所以本质上就是kv查询,用redis或者hbase查询起来效率高
前提
- 稠密矩阵
稀疏矩阵没有打cube的必要,因为很多组合都不存在,而打cube要把所有组合枚举一遍,浪费空间和效率 - 维度可枚举
不可枚举有两种意思,一种类似与实数和整数的关系,几乎是无穷的个数。另一种是虽然可枚举,但是搜索空间极大,比如全网网民,搜索空间接近几个亿,相当于不可枚举,这种情况下,打cube将会耗费极大的存储空间
优点
- 非常容易实现
- 效率高
- 可以实现olap的基本需求
缺点
- 局限性很大,有数据前提
- 需要额外的空间,空间的复杂度跟组合的搜索空间等同
- 只能实现查询实时性,插入速度慢,需要牺牲数据实时性,批量插入